| Name
|
Plot
|
Function, 
|
Derivative of  , , 
|
Range
|
Order of continuity
|
| Identity
|

|

|

|

|

|
| Binary step
|

|

|

|

|

|
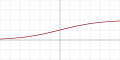
| Logistic, sigmoid, or soft step
|
|

|

|

|
|
| Hyperbolic tangent (tanh)
|

|

|

|

|
|
| Soboleva modified hyperbolic tangent (smht)
|

|

|
|
|
|
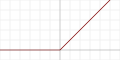
| Rectified linear unit (ReLU)[8]
|
|

|

|

|

|
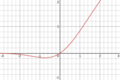
| Gaussian Error Linear Unit (GELU)[2]
|
|

|

|

|
|
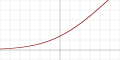
| Softplus[9]
|
|

|

|

|
|
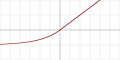
| Exponential linear unit (ELU)[10]
|
|

- with parameter

|

|

|

|
| Scaled exponential linear unit (SELU)[11]
|

|

- with parameters
 and and 
|

|

|
|
| Leaky rectified linear unit (Leaky ReLU)[12]
|

|

|

|
|
|
| Parametric rectified linear unit (PReLU)[13]
|
|

- with parameter
|

|
|
|
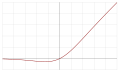
| Sigmoid linear unit (SiLU,[2] Sigmoid shrinkage,[14] SiL,[15] or Swish-1[16])
|
|

|

|

|
|
| Gaussian
|

|

|

|
![{\displaystyle (0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7e70f9c241f9faa8e9fdda2e8b238e288807d7a4)
|
|





































