The Pareto distribution, named after the Italian civil engineer, economist, and sociologistVilfredo Pareto,[2] is a power-lawprobability distribution that is used in description of social, quality control, scientific, geophysical, actuarial, and many other types of observable phenomena; the principle originally applied to describing the distribution of wealth in a society, fitting the trend that a large portion of wealth is held by a small fraction of the population.[3][4] The Pareto principle or "80-20 rule" stating that 80% of outcomes are due to 20% of causes was named in honour of Pareto, but the concepts are distinct, and only Pareto distributions with shape value (α) of log45 ≈ 1.16 precisely reflect it. Empirical observation has shown that this 80-20 distribution fits a wide range of cases, including natural phenomena[5] and human activities.[6][7]
Definitions
If X is a random variable with a Pareto (Type I) distribution,[8] then the probability that X is greater than some number x, i.e., the survival function (also called tail function), is given by
where xm is the (necessarily positive) minimum possible value of X, and α is a positive parameter. The type I Pareto distribution is characterized by a scale parameterxm and a shape parameterα, which is known as the tail index. If this distribution is used to model the distribution of wealth, then the parameter α is called the Pareto index.
When plotted on linear axes, the distribution assumes the familiar J-shaped curve which approaches each of the orthogonal axes asymptotically. All segments of the curve are self-similar (subject to appropriate scaling factors). When plotted in a log-log plot, the distribution is represented by a straight line.
The conditional probability distribution of a Pareto-distributed random variable, given the event that it is greater than or equal to a particular number exceeding , is a Pareto distribution with the same Pareto index but with minimum instead of . This implies that the conditional expected value (if it is finite, i.e. ) is proportional to . In case of random variables that describe the lifetime of an object, this means that life expectancy is proportional to age, and is called the Lindy effect or Lindy's Law.[10]
A characterization theorem
Suppose are independent identically distributedrandom variables whose probability distribution is supported on the interval for some . Suppose that for all , the two random variables and are independent. Then the common distribution is a Pareto distribution.[citation needed]
The characteristic curved 'long tail' distribution, when plotted on a linear scale, masks the underlying simplicity of the function when plotted on a log-log graph, which then takes the form of a straight line with negative gradient: It follows from the formula for the probability density function that for x ≥ xm,
Since α is positive, the gradient −(α + 1) is negative.
There is a hierarchy [8][12] of Pareto distributions known as Pareto Type I, II, III, IV, and Feller–Pareto distributions.[8][12][13] Pareto Type IV contains Pareto Type I–III as special cases. The Feller–Pareto[12][14] distribution generalizes Pareto Type IV.
Pareto types I–IV
The Pareto distribution hierarchy is summarized in the next table comparing the survival functions (complementary CDF).
When μ = 0, the Pareto distribution Type II is also known as the Lomax distribution.[15]
In this section, the symbol xm, used before to indicate the minimum value of x, is replaced by σ.
Pareto distributions
Support
Parameters
Type I
Type II
Lomax
Type III
Type IV
The shape parameter α is the tail index, μ is location, σ is scale, γ is an inequality parameter. Some special cases of Pareto Type (IV) are
The finiteness of the mean, and the existence and the finiteness of the variance depend on the tail index α (inequality index γ). In particular, fractional δ-moments are finite for some δ > 0, as shown in the table below, where δ is not necessarily an integer.
Moments of Pareto I–IV distributions (case μ = 0)
Condition
Condition
Type I
Type II
Type III
Type IV
Feller–Pareto distribution
Feller[12][14] defines a Pareto variable by transformation U = Y−1 − 1 of a beta random variable ,Y, whose probability density function is
then W has a Feller–Pareto distribution FP(μ, σ, γ, γ1, γ2).[8]
If and are independent Gamma variables, another construction of a Feller–Pareto (FP) variable is[16]
and we write W ~ FP(μ, σ, γ, δ1, δ2). Special cases of the Feller–Pareto distribution are
Inverse-Pareto Distribution / Power Distribution
When a random variable follows a pareto distribution, then its inverse follows an Inverse Pareto distribution.
Inverse Pareto distribution is equivalent to a Power distribution[17]
Relation to the exponential distribution
The Pareto distribution is related to the exponential distribution as follows. If X is Pareto-distributed with minimum xm and index α, then
is exponentially distributed with rate parameter α. Equivalently, if Y is exponentially distributed with rate α, then
is Pareto-distributed with minimum xm and index α.
This can be shown using the standard change-of-variable techniques:
The last expression is the cumulative distribution function of an exponential distribution with rate α.
Pareto distribution can be constructed by hierarchical exponential distributions.[18] Let
and
. Then we have and, as a result, .
More in general, if (shape-rate parametrization) and , then .
Equivalently, if and , then .
Relation to the log-normal distribution
The Pareto distribution and log-normal distribution are alternative distributions for describing the same types of quantities. One of the connections between the two is that they are both the distributions of the exponential of random variables distributed according to other common distributions, respectively the exponential distribution and normal distribution. (See the previous section.)
Relation to the generalized Pareto distribution
The Pareto distribution is a special case of the generalized Pareto distribution, which is a family of distributions of similar form, but containing an extra parameter in such a way that the support of the distribution is either bounded below (at a variable point), or bounded both above and below (where both are variable), with the Lomax distribution as a special case. This family also contains both the unshifted and shifted exponential distributions.
The Pareto distribution with scale and shape is equivalent to the generalized Pareto distribution with location , scale and shape and, conversely, one can get the Pareto distribution from the GPD by taking and if .
The bounded (or truncated) Pareto distribution has three parameters: α, L and H. As in the standard Pareto distribution α determines the shape. L denotes the minimal value, and H denotes the maximal value.
The purpose of the Symmetric and Zero Symmetric Pareto distributions is to capture some special statistical distribution with a sharp probability peak and symmetric long probability tails. These two distributions are derived from the Pareto distribution. Long probability tails normally means that probability decays slowly, and can be used to fit a variety of datasets. But if the distribution has symmetric structure with two slow decaying tails, Pareto could not do it. Then Symmetric Pareto or Zero Symmetric Pareto distribution is applied instead.[20]
The Cumulative distribution function (CDF) of Symmetric Pareto distribution is defined as following:[20]
The corresponding probability density function (PDF) is:[20]
This distribution has two parameters: a and b. It is symmetric by b. Then the mathematic expectation is b. When, it has variance as following:
The CDF of Zero Symmetric Pareto (ZSP) distribution is defined as following:
The corresponding PDF is:
This distribution is symmetric by zero. Parameter a is related to the decay rate of probability and (a/2b) represents peak magnitude of probability.[20]
The likelihood function for the Pareto distribution parameters α and xm, given an independent samplex = (x1, x2, ..., xn), is
Therefore, the logarithmic likelihood function is
It can be seen that is monotonically increasing with xm, that is, the greater the value of xm, the greater the value of the likelihood function. Hence, since x ≥ xm, we conclude that
To find the estimator for α, we compute the corresponding partial derivative and determine where it is zero:
Malik (1970)[23] gives the exact joint distribution of . In particular, and are independent and is Pareto with scale parameter xm and shape parameter nα, whereas has an inverse-gamma distribution with shape and scale parameters n − 1 and nα, respectively.
Occurrence and applications
General
Vilfredo Pareto originally used this distribution to describe the allocation of wealth among individuals since it seemed to show rather well the way that a larger portion of the wealth of any society is owned by a smaller percentage of the people in that society. He also used it to describe distribution of income.[4] This idea is sometimes expressed more simply as the Pareto principle or the "80-20 rule" which says that 20% of the population controls 80% of the wealth.[24] As Michael Hudson points out (The Collapse of Antiquity [2023] p. 85 & n.7) "a mathematical corollary [is] that 10% would have 65% of the wealth, and 5% would have half the national wealth.” However, the 80-20 rule corresponds to a particular value of α, and in fact, Pareto's data on British income taxes in his Cours d'économie politique indicates that about 30% of the population had about 70% of the income.[citation needed] The probability density function (PDF) graph at the beginning of this article shows that the "probability" or fraction of the population that owns a small amount of wealth per person is rather high, and then decreases steadily as wealth increases. (The Pareto distribution is not realistic for wealth for the lower end, however. In fact, net worth may even be negative.) This distribution is not limited to describing wealth or income, but to many situations in which an equilibrium is found in the distribution of the "small" to the "large". The following examples are sometimes seen as approximately Pareto-distributed:
All four variables of the household's budget constraint: consumption, labor income, capital income, and wealth.[25]
The sizes of human settlements (few cities, many hamlets/villages)[26][27]
File size distribution of Internet traffic which uses the TCP protocol (many smaller files, few larger ones)[26]
Severity of large casualty losses for certain lines of business such as general liability, commercial auto, and workers compensation.[31][32]
Amount of time a user on Steam will spend playing different games. (Some games get played a lot, but most get played almost never.) [2][original research?]
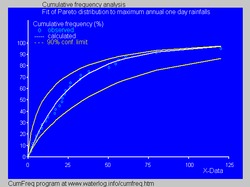
In hydrology the Pareto distribution is applied to extreme events such as annually maximum one-day rainfalls and river discharges.[33] The blue picture illustrates an example of fitting the Pareto distribution to ranked annually maximum one-day rainfalls showing also the 90% confidence belt based on the binomial distribution. The rainfall data are represented by plotting positions as part of the cumulative frequency analysis.
In Electric Utility Distribution Reliability (80% of the Customer Minutes Interrupted occur on approximately 20% of the days in a given year).
Relation to Zipf's law
The Pareto distribution is a continuous probability distribution. Zipf's law, also sometimes called the zeta distribution, is a discrete distribution, separating the values into a simple ranking. Both are a simple power law with a negative exponent, scaled so that their cumulative distributions equal 1. Zipf's can be derived from the Pareto distribution if the values (incomes) are binned into ranks so that the number of people in each bin follows a 1/rank pattern. The distribution is normalized by defining so that where is the generalized harmonic number. This makes Zipf's probability density function derivable from Pareto's.
where and is an integer representing rank from 1 to N where N is the highest income bracket. So a randomly selected person (or word, website link, or city) from a population (or language, internet, or country) has probability of ranking .
Relation to the "Pareto principle"
The "80–20 law", according to which 20% of all people receive 80% of all income, and 20% of the most affluent 20% receive 80% of that 80%, and so on, holds precisely when the Pareto index is . This result can be derived from the Lorenz curve formula given below. Moreover, the following have been shown[34] to be mathematically equivalent:
Income is distributed according to a Pareto distribution with index α > 1.
There is some number 0 ≤ p ≤ 1/2 such that 100p % of all people receive 100(1 − p)% of all income, and similarly for every real (not necessarily integer) n > 0, 100pn % of all people receive 100(1 − p)n percentage of all income. α and p are related by
This does not apply only to income, but also to wealth, or to anything else that can be modeled by this distribution.
This excludes Pareto distributions in which 0 < α ≤ 1, which, as noted above, have an infinite expected value, and so cannot reasonably model income distribution.
Relation to Price's law
Price's square root law is sometimes offered as a property of or as similar to the Pareto distribution. However, the law only holds in the case that . Note that in this case, the total and expected amount of wealth are not defined, and the rule only applies asymptotically to random samples. The extended Pareto Principle mentioned above is a far more general rule.
Lorenz curve and Gini coefficient
Lorenz curves for a number of Pareto distributions. The case α = ∞ corresponds to perfectly equal distribution (G = 0) and the α = 1 line corresponds to complete inequality (G = 1)
The Lorenz curve is often used to characterize income and wealth distributions. For any distribution, the Lorenz curve L(F) is written in terms of the PDF f or the CDF F as
where x(F) is the inverse of the CDF. For the Pareto distribution,
and the Lorenz curve is calculated to be
For the denominator is infinite, yielding L=0. Examples of the Lorenz curve for a number of Pareto distributions are shown in the graph on the right.
According to Oxfam (2016) the richest 62 people have as much wealth as the poorest half of the world's population.[35] We can estimate the Pareto index that would apply to this situation. Letting ε equal we have:
or
The solution is that α equals about 1.15, and about 9% of the wealth is owned by each of the two groups. But actually the poorest 69% of the world adult population owns only about 3% of the wealth.[36]
The Gini coefficient is a measure of the deviation of the Lorenz curve from the equidistribution line which is a line connecting [0, 0] and [1, 1], which is shown in black (α = ∞) in the Lorenz plot on the right. Specifically, the Gini coefficient is twice the area between the Lorenz curve and the equidistribution line. The Gini coefficient for the Pareto distribution is then calculated (for ) to be
^ abPareto, Vilfredo, Cours d'Économie Politique: Nouvelle édition par G.-H. Bousquet et G. Busino, Librairie Droz, Geneva, 1964, pp. 299–345. Original book archived
^ abFeller, W. (1971). An Introduction to Probability Theory and its Applications. Vol. II (2nd ed.). New York: Wiley. p. 50. "The densities (4.3) are sometimes called after the economist Pareto. It was thought (rather naïvely from a modern statistical standpoint) that income distributions should have a tail with a density ~ Ax−α as x → ∞".
^Lomax, K. S. (1954). "Business failures. Another example of the analysis of failure data". Journal of the American Statistical Association. 49 (268): 847–52. doi:10.1080/01621459.1954.10501239.
^ abcdHuang, Xiao-dong (2004). "A Multiscale Model for MPEG-4 Varied Bit Rate Video Traffic". IEEE Transactions on Broadcasting. 50 (3): 323–334. doi:10.1109/TBC.2004.834013.
^ abcdeReed, William J.; et al. (2004). "The Double Pareto-Lognormal Distribution – A New Parametric Model for Size Distributions". Communications in Statistics – Theory and Methods. 33 (8): 1733–53. CiteSeerX10.1.1.70.4555. doi:10.1081/sta-120037438. S2CID13906086.
^Schroeder, Bianca; Damouras, Sotirios; Gill, Phillipa (2010-02-24). "Understanding latent sector error and how to protect against them"(PDF). 8th Usenix Conference on File and Storage Technologies (FAST 2010). Retrieved 2010-09-10. We experimented with 5 different distributions (Geometric, Weibull, Rayleigh, Pareto, and Lognormal), that are commonly used in the context of system reliability, and evaluated their fit through the total squared differences between the actual and hypothesized frequencies (χ2 statistic). We found consistently across all models that the geometric distribution is a poor fit, while the Pareto distribution provides the best fit.
Pareto, Vilfredo (1965). Librairie Droz (ed.). Ecrits sur la courbe de la répartition de la richesse. Œuvres complètes : T. III. p. 48. ISBN9782600040211.
Pareto, Vilfredo (1895). "La legge della domanda". Giornale Degli Economisti. 10: 59–68.














![{\displaystyle x_{\mathrm {m} }{\sqrt[{\alpha }]{2))}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ef1a9e02a1d60cf9cd611b13188b078509904bc7)












![{\displaystyle \operatorname {Var} (X)={\begin{cases}\infty &\alpha \in (1,2],\\\left({\frac {x_{\mathrm {m} )){\alpha -1))\right)^{2}{\frac {\alpha }{\alpha -2))&\alpha >2.\end{cases))}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bda6ae1a69ab2c130545abd2053226a4d6510558)

![{\displaystyle M\left(t;\alpha ,x_{\mathrm {m} }\right)=\operatorname {E} \left[e^{tX}\right]=\alpha (-x_{\mathrm {m} }t)^{\alpha }\Gamma (-\alpha ,-x_{\mathrm {m} }t)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0b03963721b9c85e5030aa7a26056af4ef07a4e4)
















![{\displaystyle \left[{\frac {x}{\sigma ))\right]^{-\alpha ))](https://wikimedia.org/api/rest_v1/media/math/render/svg/debc11c1d4259755203a2e95e5171e4b2c28b695)


![{\displaystyle \left[1+{\frac {x-\mu }{\sigma ))\right]^{-\alpha ))](https://wikimedia.org/api/rest_v1/media/math/render/svg/c1c05d4c866664355381925ebc7f1d6854a8b4b2)


![{\displaystyle \left[1+{\frac {x}{\sigma ))\right]^{-\alpha ))](https://wikimedia.org/api/rest_v1/media/math/render/svg/b5f6d8660cc815594ad3f6fbbba08e57eaa4bf12)

![{\displaystyle \left[1+\left({\frac {x-\mu }{\sigma ))\right)^{1/\gamma }\right]^{-1))](https://wikimedia.org/api/rest_v1/media/math/render/svg/08d45a24039951a4a164feb7f48ee05c3b852a28)

![{\displaystyle \left[1+\left({\frac {x-\mu }{\sigma ))\right)^{1/\gamma }\right]^{-\alpha ))](https://wikimedia.org/api/rest_v1/media/math/render/svg/a95750fc2c1674af87b4f4d3115af6dbf9728743)




![{\displaystyle \operatorname {E} [X]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/44dd294aa33c0865f58e2b1bdaf44ebe911dbf93)
![{\displaystyle \operatorname {E} [X^{\delta }]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fab8f72a2621c18717c6afbb3a3772ca30a36b4d)